Update 2: Moving Towards Megapoll Assembly
Contents
Update 2: Moving Towards Megapoll Assembly¶
Concise Project Refresher¶
Our project is using approximately 140 surveys on climate opinion in order to determine how different demographics influence opinions on climate change. The surveys we are using are public data that ask a variety of questions on the importance and validity of climate change, as well as demographic variables of the respondent such as education level, income, race, age, and gender across multiple countries.
Initial Effort¶
For most of the quarter so far we have been sorting out 7 demographics from 140 different surveys. Specifically, we are in the process of data cleaning; we are taking raw data from the surveys and, while keeping data in exactly the same format, removing/adjusting/correcting any existent data validity issues. We have also been removing records that are flawed, inputting null values, and using substitute solutions to clean up our data. Another issue we have to address is certain questions being re-written for different regions (ie. income bracket questions may have different response values), so we have decided to merge all of the values into “_mod” variables which essentially re-code these responses in a uniform way to eventually merge them into the megapoll. This is essentially a dataset containing every single survey respondents’ (~ 3 million) relevant responses regarding climate concern questions, only it does not contain any information besides their coded response and region at the moment. After our merging, however, it will contain all of the respondents’ associated demographics as well. Overall this is associated with our two objectives for this quarter, which have been continuing to work through pre-processing the remaining surveys and beginning to add the demographic variables to the megapoll.
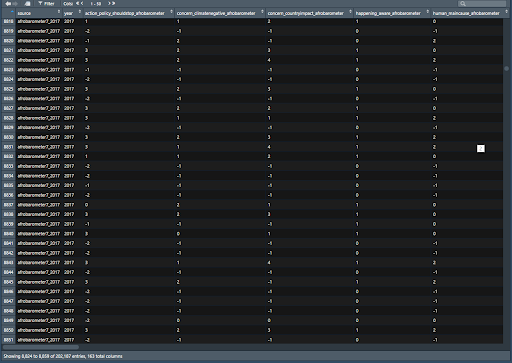 Above: Example snippet of the afrobarometer_7 section of responses in the Megapoll
Above: Example snippet of the afrobarometer_7 section of responses in the Megapoll
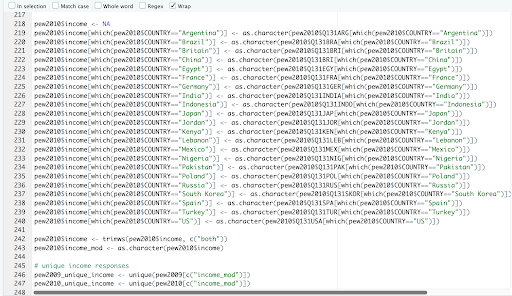 *Above: making a “_mod” variable to account for different occurrences of a single question divided by countries in survey responses
*Above: making a “_mod” variable to account for different occurrences of a single question divided by countries in survey responses
Results¶
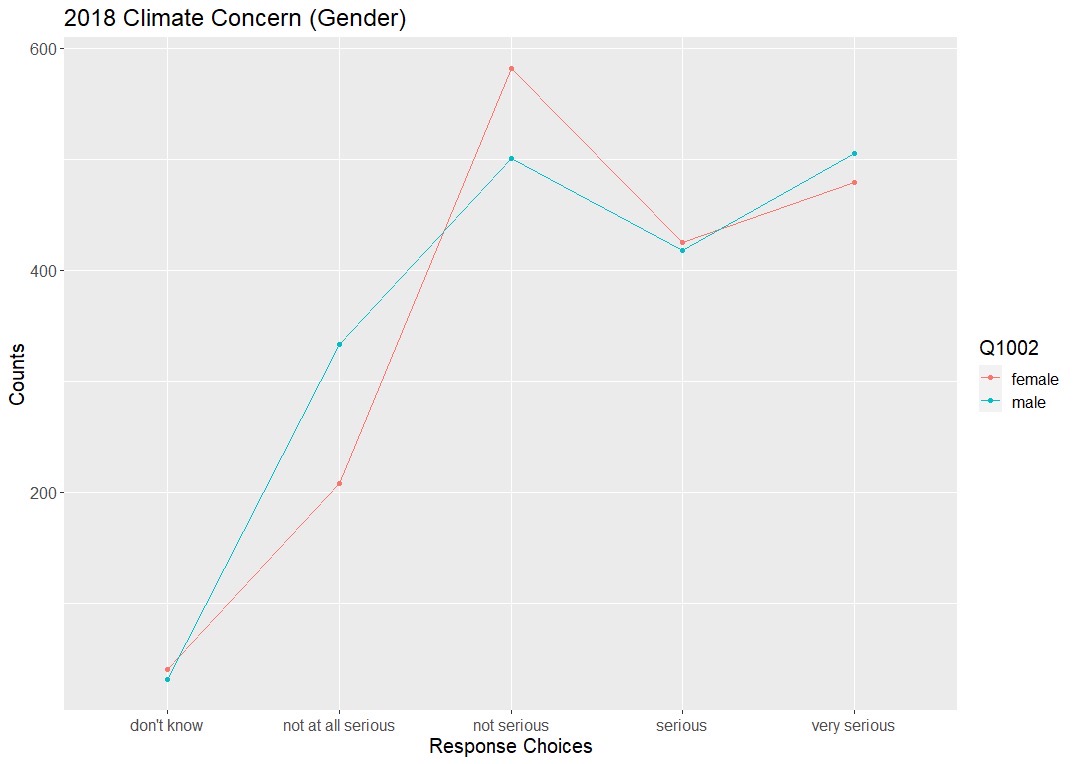 Prior to working with the data, we made predictions of demographic variables that are going to have greater climate concern than other variables.As a group, we predicted that women would be more pro climate than males, educated individuals would be more pro climate than uneducated individuals, and families with less/ no children would be more pro climate than families with multiple children. Despite not having a complete dataset to create a model on quite yet, we have looked into some individual surveys to draw conclusions from. The graph above displays the respondent’s opinions of climate concern on a scale ranging from not at all serious to very serious. From the graph we can see that the different genders follow fairly similar trends in their opinion on the severity of climate change. The biggest difference in this particular survey shows that more females think that climate change is not serious than males who think climate change is not serious. This outcome is slightly different than our predicted results of women thinking climate change is more serious at a higher rate than men. However, this is only one survey from one country and does not at all reflect results as a whole. The graph corresponds to a survey that was taken in Egypt, Libya, and Kuwait. Perhaps in these countries, women are not aware of the implications of climate concern and therefore do not see it as a serious concern. Without taking all surveys from countries spanning across the world into account, we cannot make accurate predictions on the global opinion on climate change. However, looking into each individual survey can reveal a lot of information on each country’s individual concern.
Prior to working with the data, we made predictions of demographic variables that are going to have greater climate concern than other variables.As a group, we predicted that women would be more pro climate than males, educated individuals would be more pro climate than uneducated individuals, and families with less/ no children would be more pro climate than families with multiple children. Despite not having a complete dataset to create a model on quite yet, we have looked into some individual surveys to draw conclusions from. The graph above displays the respondent’s opinions of climate concern on a scale ranging from not at all serious to very serious. From the graph we can see that the different genders follow fairly similar trends in their opinion on the severity of climate change. The biggest difference in this particular survey shows that more females think that climate change is not serious than males who think climate change is not serious. This outcome is slightly different than our predicted results of women thinking climate change is more serious at a higher rate than men. However, this is only one survey from one country and does not at all reflect results as a whole. The graph corresponds to a survey that was taken in Egypt, Libya, and Kuwait. Perhaps in these countries, women are not aware of the implications of climate concern and therefore do not see it as a serious concern. Without taking all surveys from countries spanning across the world into account, we cannot make accurate predictions on the global opinion on climate change. However, looking into each individual survey can reveal a lot of information on each country’s individual concern.
Next Steps¶
Based on our current progress, the next goal we are actively working towards is incorporating all the demographic variables into the ENVENT lab’s megapoll so that we can begin modeling what the best demographic predictors of climate concern are.
After adding to the megapoll, we will be able to start making general exploratory plots to better understand the global trends of climate concern as opposed to what we could gather from the region-locked surveys alone. From there, we can begin to develop more sophisticated ML models to identify which of the variables (or combinations of them) are the best demographic predictors of climate concern.
So what do we need to accomplish to start working towards this goal? First and foremost we will continue chipping away at the 140+ surveys and gathering those demographic variables. However many still need to be standardized before they can be properly merged into the megapoll - we accomplish this through the “_mod” variables;
- We are each actively working to acquaint ourselves with the ENVENT labs code for adding new variables into the megapoll and will continue to do so;
- We must keep in mind and develop more project goals, which will continue to guide our work while preprocessing; Keep in mind the end goals and time our work accordingly!